Lambda Function Read Fixed Length Data File to S3
Making Sense of Big Information
On the Fly Transformation of Preparation Data with Amazon S3 Object Lambda
Reduce CPU Load on the Preparation Instance by Processing Data During its Retrieval
![]()
Two months agone (in March of 2021) AWS appear the Amazon S3 Object Lambda characteristic, a new capability that enables one to process data that is being retrieved from Amazon S3 before information technology reaches the calling application. The announcement highlights how this characteristic tin can be used to provide different views of the data to different clients and describes its advantages over other solutions in terms of complexity and cost:
To provide different views of data to multiple applications, there are currently ii options. You lot either create, store, and maintain additional derivative copies of the data, so that each application has its own custom dataset, or you build and manage infrastructure as a proxy layer in forepart of S3 to intercept and process data as it is requested. Both options add together complication and costs, so the S3 team decided to build a better solution.
— Quote from the characteristic declaration.
Excited by the prospects of this new feature, nosotros decided to evaluate its employ in a deep learning training scenario.
Training Data Transformation with Amazon S3 Object Lambda
The trainin g scenario we will evaluate is ane in which nosotros have a very large training dataset, residing in Amazon S3, that we stream into a grooming session running on one or more than GPUs on one or more than Amazon EC2 preparation instances. In a typical setting the input training data might undergo a serial of transformations, augmentations, warping, shuffling, batching, and other operations on the training devices' CPU cores before being fed into the GPU. This series of operations is commonly referred to as the pre-processing pipeline. A ciphering intensive pre-processing pipeline might lead to a CPU bottleneck in the training pipeline, a situation in which the GPU is underutilized every bit it waits to exist fed past the CPU. This common scenario is quite undesirable; the GPU is the almost expensive training resources and our goal should exist to maximize its utilization so as to minimize our overall training costs.
In a previous blog post we expanded on information pre-processing bottlenecks and reviewed some ways to overcome them. Despite all of your attempts, you might notice that your CPU processing continues to overburden your bachelor resources. By offering us the opportunity to perform some of the processing of the grooming data earlier it reaches the device, the Amazon S3 Object Lambda feature would seem like simply what the md ordered.
The specific use case I have chosen to demonstrate is 1 in which we are training a TensorFlow model on training data that has been stored in Amazon S3 in the webdataset file format. Webdataset is a file format designed for training with big datasets in which samples are stored equally collections of POSIX tar archives. By using webdataset, sample features can be stored and processed in their original formats, e.thousand. images as jpgs, sound files as wavs, python structures as pkl files, etc. For more than on webdataset see the Github project folio, the pip installation folio, and this mail service. While the webdataset package includes APIs for defining a pytorch compatible dataset, it does not, equally of the time of this writing, include built in back up for TensorFlow. To conform with the TensorFlow training session we will perform on the wing conversion of the data to the TensorFlow friendly TFRecord format. The selection of this use case was somewhat arbitrary. 1 can just as easily choose to assess Amazon S3 Object Lambda with any other blazon of data transformation.
In order to assess the suitability of Amazon S3 Object Lambda for our chosen utilise case, nosotros volition need to consider the culling solutions. Here are some options:
- Create and maintain a copy of the dataset in TFRecord format in S3 to exist used for model preparation. There are several disadvantages to this choice including the demand for additional storage resources and the demand to recreate the preparation information any fourth dimension a alter is made to the underlying data.
- Feed the data in webdataset format into the training device. Build a TensorFlow dataset that receives this format, or perform the format conversion on the training device. The danger of this approach is the added contention for CPU resources and the possibility of GPU nether-utilization.
- Create a defended cluster of CPU cores that will pull the data from S3, perform the format conversion, and feed the result to the training device.
Our evaluation of the use of Amazon S3 Object Lambda in this scenario will encompass 2 aspects:
- Cost — what are the price implications of using the Amazon S3 Object Lambda as opposed to the other options?
- Training throughput — how does using Amazon S3 Object Lambda impact the training throughput (measured by the number of samples per 2d that are fed into the model)?
While my own personal involvement in writing this post is to demonstrate and evaluate the performance of the feature, for reasons that will become immediately articulate, we volition first by discussing the price implications of using the feature. Nosotros will then demonstrate the conversion of data stored in the webdataset format into TFRecord format using Amazon S3 Object Lambda. To complete our evaluation we will compare the implications of using Amazon S3 Object Lambda on the training throughput with some of the culling solutions.
I would similar to thank my colleague Max Rabin for his help in setting upwardly and running the experiments described in this postal service.
Amazon S3 Object Lambda Cost Analysis
The price of using Amazon S3 Object Lambda can be plant on the Amazon S3 pricing page under the S3 Object Lambda tab. As described there, the cost of the feature is comprised of 3 parts: the typical cost of pulling information from Amazon S3, the cost of running the AWS Lambda function, and an additional cost based on the amount of information that is passed to the calling application. Here is an excerpt from the pricing page (captured on May 8th 2021).
When yous use S3 Object Lambda, your S3 Go request invokes an AWS Lambda office that you define. This function will procedure your data and render a processed object dorsum to your application. In the U.s.a. East (N. Virginia) Region you pay $0.0000167 per GB-second for the duration of your AWS Lambda office, and $0.twenty per 1M AWS Lambda requests. Y'all also pay $0.0004 per 1,000 requests for all S3 Get requests that are invoked by your Lambda function, and a $0.005 per-GB fee for the data S3 Object Lambda returns to your application.
— Excerpt from https://aws.amazon.com/s3/pricing/
Suppose that our dataset is 100 TB in size, broken into one,000,000 files of size 100 MB each. The typical cost of a single data traversal (ane epoch) would be a mere $0.40. The added price of pulling the information via Amazon S3 Object Lambda would be 100,000 x 0.005 = $500! And this is before because the cost of running the Lambda part itself. Patently, this price should be evaluated in its total context — i.e. how information technology impacts the overall cost of training. Only barring any arithmetic errors (which should not exist ruled out) it would seem that the current pricing model of the characteristic is non suited for data hungry applications such every bit auto learning. At the very to the lowest degree, it warrants a closer look at the costs of alternative solutions.
Creating and maintaining derivatives of the data in Amazon S3: Despite the inconvenience and "ugliness" of this kind of solution, it is likely to exist more cost effective. Data storage is relatively inexpensive and while we would still require computation resources for applying the data transformation, this would only be run one time per training task (as opposed to running it on every data traversal). The problem is that this solution is not always an option. Often a deep learning training session requires applying random augmentations on the input data. While creating many copies of the information with random transformations is possible, it is highly impractical. And a collection of such fixed perturbations, as large as it might be, may not result in the same affect on training every bit applying the random operations on the pre-processing pipeline.
Transforming the information on the training device: Despite our desire to maximize the utilization of GPU resources, our cost analysis compels us to revisit the price of resource under-utilization. Clearly, the cost volition depend on a number of factors including: 1. the types and number of training devices and 2. the amount of time it takes to traverse the information. Lets consider the post-obit example of how the cost can be assessed: Suppose that our GPU preparation resource costs $28 dollars per hour, that our information transformation reduces utilization to 25% (from 100%), and that i traversal of our 100 TB of data requires twenty hours. Nosotros find that the added cost, per information traversal, of running the transformation on the training device is 0.75 x 20 x 28=$420. In this example the cost is lower than that of the Amazon S3 Object Lambda function but it is not hard to fathom situations where information technology would be a less attractive solution.
Performing the data transformation on a dedicated CPU cluster: In the aforementioned post on the topic of addressing CPU computation bottlenecks, we demonstrated the use of the tf.data service for offloading information pre-processing onto auxiliary CPU machines. If an existing framework such as tf.information service or AIStore supports your data transformation requirements, its employ is likely to be more cost efficient than Amazon S3 Object Lambda. Otherwise, you may need to blueprint and create your ain solution. While such an endeavor would probable reap benefits in the long term, it is not a petty undertaking, by any stretch of the imagination.
The price analysis nosotros performed in this section was incomplete. A comprehensive cost evaluation should take into business relationship the price of running the AWS Lambda function. It should also consider how using Amazon S3 Object Lambda impacts the training throughput and thus the overall training runtime and cost. More than on this beneath.
Building the Amazon S3 Object Lambda Solution
Equally described in the AWS documentation setting up Amazon S3 Object Lambda requires two main steps: defining and deploying the AWS Lambda function and creating the Object Lambda admission point. We presume that the training data has already been prepared in webdataset format. You can find a data cosmos case in an appendix to this post.
AWS Lambda Function Creation
We chose to define, build, and deploy the Lambda part using the AWS Serverless Awarding Model (AWS SAM). Like to the case described in the "Hullo World" tutorial, we created a Lambda function called convert_wds2tf. The definition of the office is comprised of four parts:
- A TFRecord writer class, TFRecordWriter, adjusted from here.
- A webdataset file parser, wds_iter.
- A format converter course that receives a wds_iter and returns the corresponding TFRecord file. The converter can render a single TFRecord file (via the read office) or an iterator over chunks of TFRecord samples. The current __iter__ implementation is difficult coded to return 100 samples per clamper.
- The lambda_handler part which pulls the webdataset file from S3, creates a wds_iter for traversing it, and converts it to TFRecord output using the Converter course.
import boto3, requests, struct, imageio, io, re
import tarfile, crc32c, numpy as np
from botocore.config import Config
# python code generated past the protocol buffer compiler
from pb import example_pb2 # TFRecordWriter adapted from here
class TFRecordWriter:
def __init__(cocky, data_path=None,file_obj=None):
cocky.file = open up(data_path, "wb") if data_path
else file_obj def write(self, datum):
record = TFRecordWriter.serialize_tf_example(datum)
length = len(record)
length_bytes = struct.pack("<Q", length)
cocky.file.write(length_bytes)
cocky.file.write(TFRecordWriter.masked_crc(length_bytes))
self.file.write(tape)
self.file.write(TFRecordWriter.masked_crc(record)) @staticmethod
def masked_crc(data):
mask = 0xa282ead8
crc = crc32c.crc32c(data)
masked = ((crc >> fifteen) | (crc << 17)) + mask
masked = np.uint32(masked)
masked_bytes = struct.pack("<I", masked)
return masked_bytes @staticmethod
def serialize_tf_example(datum):
feature_map = {
"byte": lambda f: example_pb2.Feature(
bytes_list=example_pb2.BytesList(value=f)),
"int": lambda f: example_pb2.Feature(
int64_list=example_pb2.Int64List(value=f))
} def serialize(value, dtype):
if not isinstance(value, (list, tuple, np.ndarray)):
value = [value]
return feature_map[dtype](value) features = {key: serialize(value, dtype)
for key, (value, dtype) in datum.items()}
example_proto = example_pb2.Example(
features=example_pb2.Features(feature=features))
return example_proto.SerializeToString() # iterate over a wds dataset
def wds_iter(path):
def my_png_decoder(value):
return imageio.imread(io.BytesIO(value))
def my_cls_decoder(value):
return int(value.decode("utf-eight").strip('][')) stream = tarfile.open(fileobj=path, mode="r|*")
record = {}
count = 0
for tarinfo in stream:
filename = tarinfo.proper name
key, suffix = re.split('\.',filename)
if not tape or record['fundamental'] != key:
if 'information' in record and 'label' in record:
count += 1
yield tape['data'], record['label']
record = {'central':cardinal}
value = stream.extractfile(tarinfo).read()
if suffix == 'cls':
record['label'] = int(
value.decode("utf-8").strip(']['))
elif suffix == 'png':
record['data'] = imageio.imread(io.BytesIO(value))
if 'information' in record and 'label' in tape:
yield record['information'], record['label'] class Converter:
def __init__(self, dataset):
self.dataset = dataset def read(cocky, size=None):
transformed_object = io.BytesIO()
record_writer = TFRecordWriter(
file_obj=transformed_object)
for information, label in self.dataset:
record_writer.write({"image": (data.tobytes(),"byte"),
"label": (characterization,"int")})
transformed_object.seek(0)
return transformed_object.read() def __iter__(self):
transformed_object = io.BytesIO()
record_writer = TFRecordWriter(
file_obj=transformed_object)
count = 0
for data, characterization in cocky.dataset:
if count>0 and count%100 == 0:
transformed_object.seek(0)
yield transformed_object.read()
transformed_object = io.BytesIO()
record_writer = TFRecordWriter(
file_obj=transformed_object)
record_writer.write({"image": (data.tobytes(),"byte"),
"label": (characterization, "int")})
count+=ane
transformed_object.seek(0)
yield transformed_object.read() def lambda_handler(event, context):
stream_chunks = False
object_get_context = event["getObjectContext"]
request_route = object_get_context["outputRoute"]
request_token = object_get_context["outputToken"]
s3_url = object_get_context["inputS3Url"]
# Get object from S3
r = requests.get(s3_url, stream=stream_chunks)
original_object = r.content
# Transform object
convert_to_tfrecord2 = Converter(
wds_iter(io.BytesIO(original_object)))
if stream_chunks:
s3 = boto3.client('s3',
config=Config(
signature_version='s3v4',
s3={'payload_signing_enabled': False}))
body = convert_to_tfrecord2
else:
s3 = boto3.customer('s3')
body = convert_to_tfrecord2.read()
# Write object back to S3 Object Lambda
s3.write_get_object_response(
Torso=body,
RequestRoute=request_route,
RequestToken=request_token
)
return {'status_code': 200}
Our implementation demonstrates the selection of streaming dorsum chunked data to the calling application via the stream_chunks flag. In many cases y'all may find that this volition amend the streamlining of the solution, reduce latency, and increase throughput. Due to the fact that our client awarding will utilise TensorFlow to read the information files, and TensorFlow does not currently back up chunked data streams from S3, we have gear up stream_chunks to simulated.
Existence that this code was created for demonstrative purposes, nosotros have non invested in optimizing the implementation. Optimizing the Lambda office is extremely of import for both reducing costs and potentially reducing latency.
Pulling Data Files by Range
One of the important features offered past Amazon S3 is an API for pulling specific byte ranges within a information file. In particular, this feature enables multipart data download in which a data file is divided into parts which are downloaded in parallel. Needles to say that this tin can have a meaningful touch on on the download speed and, by extension, on the data throughput. As documented in the User Guide, S3 Object Lambda does back up retrieving data according to range and part number, although this requires special treatment. In the case of data transformation, as nosotros demonstrate here, supporting access to arbitrary ranges inside the object could be highly inefficient. A niggling implementation would require transforming the entire data file (or at least all of the data upwardly until nosotros take generated the requested range). A more than efficient implementation would crave united states to be able to map ranges of the Lambda response to ranges of the source file. Such a mapping does non ever exist. Even when information technology does, unless the calling application was programmed to request ranges that aligned perfectly with the data sample boundaries, we would still end upwardly performing more work than when pulling the total object. Our example does not include support for pulling specific ranges.
S3 Object Lambda Customer Application Case
In the example below we testify how to plan a TensorFlow TFRecordDataset that points to S3 Objects via the Object Lambda Endpoint. Since we are interested in measuring just the training information throughput, we forgo edifice a grooming model and instead iterate directly on the dataset.
import os, tensorflow as tf
#replace with your access_point and paths in s3
ap_path='s3://arn:aws:s3-object-lambda:us-due east-1:<id>:accesspoint'
path_to_s3_wds_folder='<path-to-webdataset-binder>'
path_to_s3_tfr_folder='<path-to-tfrecord-folder>'
s3_path_to_wds='s3://'+path_to_s3_wds_folder
s3_path_to_tfr='s3://'+path_to_s3_tfr_folder
ap_path_to_wds=os.path.join(ap_path,path_to_s3_wds_folder) def get_dataset(batch_size, folder_path):
autotune = tf.data.experimental.AUTOTUNE
def parse_image_function(example_proto):
image_feature_description = {
'image': tf.io.FixedLenFeature([], tf.cord),
'characterization': tf.io.FixedLenFeature([], tf.int64)
}
features = tf.io.parse_single_example(
example_proto, image_feature_description)
image = tf.io.decode_raw(features['prototype'], tf.uint8)
paradigm.set_shape([iii * 32 * 32])
image = tf.reshape(image, [32, 32, 3])
label = tf.cast(features['label'], tf.int32)
return image, label options = tf.data.Options()
options.experimental_deterministic = False
records = tf.data.Dataset.list_files(folder_path + '/*',
shuffle=True).with_options(options) ds = tf.data.TFRecordDataset(records,
num_parallel_reads=autotune).repeat()
ds = ds.map(parse_image_function, num_parallel_calls=autotune)
ds = ds.batch(batch_size)
ds = ds.prefetch(autotune)
return ds # get converted dataset via object lambda access point
ds = get_dataset(batch_size=1024, folder_path=ap_path_to_wds) # uncomment to become raw tfrecord dataset
#ds = get_dataset(batch_size=1024, folder_path=s3_path_to_tfr) round = 0
start_time = fourth dimension.time()
for x in ds:
round = round + 1
if round % 100 == 0:
print("round {}: epoch time: {}".
format(round, fourth dimension.time() - start_time))
start_time = time.time()
if round == 2000:
break
Note that the only difference between creating the TFRecord dataset generated by the Lambda part from the webdataset information source and creating the TFRecord dataset from raw TFRecord data is in the folder_path that is passed into the get_dataset office.
Unfortunately, if you attempt to run the application higher up with the default installation of the TensorFlow package information technology will fail. A few minor changes are required to be made to the TensorFlow source code, including updating the version of the AWS CPP SDK, enhancing the S3 URL parser, and disabling multipart and range based downloading from S3. The changes required are detailed in an appendix to this blog post.
For the purpose of performance comparison nosotros include a naïve implementation of building a TensorFlow dataset based on the raw webdataset data.
def get_raw_wds(batch_size):
autotune = tf.data.experimental.AUTOTUNE
options = tf.data.Options()
options.experimental_deterministic = Simulated
dataset = tf.information.Dataset.list_files(s3_path_to_wds+'/*',
shuffle=True).with_options(options)
def gen(path):
g = io.BytesIO(tf.io.read_file(path).numpy())
images = []
labels = []
for x, y in wds_iter(g):
images.suspend(10)
labels.suspend(y)
render images, labels
def make_ds(path):
images, labels = tf.py_function(func=gen, inp=[path],
Tout=(tf.uint8, tf.uint8))
return tf.data.Dataset.from_tensor_slices((images,
labels))
ds = dataset.interleave(make_ds, num_parallel_calls=autotune,
deterministic=False)
autotune = tf.data.experimental.AUTOTUNE
ds = ds.batch(batch_size)
ds = ds.repeat().prefetch(autotune)
return ds Again we emphasize that the lawmaking presented here has non undergone whatever optimization. The code and measurements are presented for sit-in purposes only.
Results
Due to both the latency associated with pulling the data via a Lambda function as well as the restrictions on multipart downloading, the S3 Object Lambda based solution could potentially result in lower throughput than when reading raw TFRecord files. The challenge is to attempt to overcome this potential latency through methods such as parallel processing. Here we compare the speed of the data traversal, measured in seconds per 100 batches of training data, for the following five experiments:
- Reading raw TensorFlow files roughly of size 150 MB each.
- Reading converted information via our S3 Object Lambda Access Point where the webdataset files are roughly of size 192 MB each.
- Reading converted data via our S3 Object Lambda Admission Betoken where the webdataset files are roughly of size eight MB each
- Reading raw webdataset files roughly of size 192 MB each
- Reading raw webdataset files roughly of size 8 MB each
Our experiments practise not include the option of performing webdataset to TFRecord conversion on an auxiliary CPU cluster. As discussed higher up, this choice has several advantages and warrants evaluation. I promise to fill this gap in a future post.
All experiments were run on a c5.4xlarge Amazon EC2 instance type.
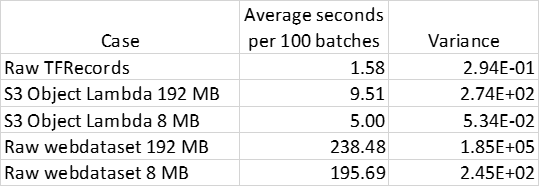
The results show that past using the S3 Object Lambda feature we were able to speed the dataset traversal past roughly 20X compared to raw webdataset traversal. At the same time, it is yet more than than iii times slower than using raw TFRecord files. We can also see that the file size has a meaningful impact on the performance of the S3 Object Lambda based solution in terms of its speed and its consistency. Information technology is quite likely that by tuning the number of parallel processes, tuning the file sizes, and implementing other optimizations to the solution, we could increment the performance of the Lambda based solution and arroyo the throughput of the raw TFRecord reader. Based on our current findings, the articulate recommendation for our use case would exist to create and maintain a copy of our dataset in TFRecord format in S3, for both performance and cost considerations.
Summary
With regards to the use of the Amazon S3 Object Lambda for on the fly transformation of input training data, we have found that both the cost model of the solution every bit well every bit the potential touch that its utilize has on the training throughput render it a less than optimal solution. Nonetheless, in cases where all other options prove impractical, too difficult, or more costly, the Amazon S3 Object Lambda choice might but come in handy.
Appendix 1 — Webdataset Creation Case
In the following lawmaking cake we demonstrate conversion of the popular cifar10 dataset to webdataset format. The sizes of the dataset shards are adamant past the maxsize and maxcount configuration settings.
import webdataset as wds
from tensorflow.keras import datasets
from PIL import Image def convert_to_wds():
(train_images, train_labels), _ = datasets.cifar10.load_data()
design = f"cifar10-%06d.brusque.tar"
temp_file = '/tmp/wds.png'
max_file_size = 1000000000
max_samples = 20000
with wds.ShardWriter(design, maxsize=max_file_size,
maxcount=max_samples) as sink:
for i in range(len(train_labels)):
im = Image.fromarray(train_images[i])
im.save(temp_file)
with open(temp_file, "rb") as stream:
png = stream.read()
cls = train_labels[i]
sample = {"__key__": "%07d" % i, "png": png, "cls": cls}
sink.write(sample)
Multiple copies of the dataset tin be created to simulate a dataset of arbitrary length.
Appendix 2 — Changes to TensorFlow Source Code
Here I describe the steps I took in order to modify and recompile TensorFlow to work with the Amazon S3 Object Lambda Solution. To pull and rebuild TensorFlow I followed the instructions on edifice TensorFlow from source. I performed this on the "2.four" branch of the TensorFlow source code. The changes I made are past no means optimal. Y'all might even consider them to exist a bit hacky. I would certainly recommend a more conscientious approach if yous opt for this solution:
Step 1 — Update the AWS C++ SDK: The current TensorFlow code compiles with a version of the AWS C++ SDK that does not back up accessing an Amazon S3 Object Lambda endpoint. To update the SDK version, y'all demand to alter the AWS bazel build dependency at workspace.bzl. I chose SDK version ane.8.186:
tf_http_archive(
name = "aws",
urls = [
"https://storage.googleapis.com/mirror.tensorflow.org/github.com/aws/aws-sdk-cpp/archive/1.8.186.tar.gz",
"https://github.com/aws/aws-sdk-cpp/annal/refs/tags/1.eight.186.tar.gz",
],
sha256 = "749322a8be4594472512df8a21d9338d7181c643a00e08a0ff12f07e831e3346",
strip_prefix = "aws-sdk-cpp-one.viii.186",
build_file = "//third_party/aws:BUILD.bazel"
) Step two — Change the S3 URI parser to support an Amazon S3 Object Lambda endpoint: In ParseS3Path function of the file tensorflow/core/platform/s3/s3_file_system.cc append the following block of lawmaking for addressing an Amazon S3 Object Lambda endpoint:
if (bucket->rfind("arn:aws", 0) == 0) {
bucket->append("/");
size_t pos = object->discover("/");
bucket->append(object->substr(0, pos));
object->erase(0, pos + 1);
} Pace 3 — Disable multipart and range based object download: This requires changes to two functions in the file tensorflow/core/platform/s3/s3_file_system.cc. The changes are highlighted in the code blocks beneath. (Note how nosotros are overloading the use of the of the use_multi_part_download_ field to indicate employ of an Amazon S3 Object Lambda endpoint. Information technology is not clean, but it works since the default value of this setting is truthful.)
NewRandomAccessFile:
Status S3FileSystem::NewRandomAccessFile(
const string& fname, TransactionToken* token,
std::unique_ptr<RandomAccessFile>* outcome,
bool use_multi_part_download) {
string bucket, object;
TF_RETURN_IF_ERROR(ParseS3Path(fname, imitation, &bucket, &object)); // in case of S3 object lambda endpoint overwrite
// multipart download
if (bucket.rfind("arn",0) == 0){
use_multi_part_download = simulated;
} bool use_mpd = this->use_multi_part_download_ &&
use_multi_part_download;
consequence->reset(new S3RandomAccessFile(
bucket, object, use_mpd,
this->GetTransferManager(
Aws::Transfer::TransferDirection::DOWNLOAD),
this->GetS3Client()));
return Condition::OK();
}
ReadS3Client:
Status ReadS3Client(uint64 showtime, size_t n, StringPiece* result,
char* scratch) const {
VLOG(3) << "ReadFile using S3Client s3://" <<
bucket_ << "/" << object_;
if (!use_multi_part_download_ && starting time > 0) {
due north = 0;
*upshot = StringPiece(scratch, n);
render Condition(error::OUT_OF_RANGE,
"Read less bytes than requested");
}
Aws::S3::Model::GetObjectRequest getObjectRequest;
getObjectRequest.WithBucket(bucket_.c_str()).
WithKey(object_.c_str());
if (use_multi_part_download_) {
string bytes = strings::StrCat("bytes=", offset,
"-", first + n - 1);
getObjectRequest.SetRange(bytes.c_str());
}
getObjectRequest.SetResponseStreamFactory([]() {
render Aws::New<Aws::StringStream>
(kS3FileSystemAllocationTag);
}); car getObjectOutcome = this->s3_client_->GetObject(
getObjectRequest);
if (!getObjectOutcome.IsSuccess()) {
auto error = getObjectOutcome.GetError();
if (error.GetResponseCode() ==
Aws::Http::HttpResponseCode::
REQUESTED_RANGE_NOT_SATISFIABLE) {
n = 0;
*result = StringPiece(scratch, n);
return Status(error::OUT_OF_RANGE,
"Read less bytes than requested");
}
return CreateStatusFromAwsError(fault);
} else {
n = getObjectOutcome.GetResult().GetContentLength();
if (use_multi_part_download_) {
getObjectOutcome.GetResult().GetBody().read(scratch, due north);
*effect = StringPiece(scratch, n);
return Status::OK();
} else {
getObjectOutcome.GetResult().GetBody().read(scratch, northward);
*event = StringPiece(scratch, n);
return Condition::OK();
}
}
}
Step 4 — Overstate the size of the collection buffer to capture total files: This change should be adapted to your files sizes. Since our files are all nether 200 MBs, doubling the size of the buffer sufficed. In the file tensorflow/cadre/kernels/data/tf_record_dataset_op.cc increase the size of kCloudTpuBlockSize:
constexpr int64 kCloudTpuBlockSize = 127LL << 21; // 254MB. Step v: Follow the instructions on the building TensorFlow from source page to create the TensorFlow wheel and install the updated package.
Source: https://towardsdatascience.com/on-the-fly-transformation-of-training-data-with-amazon-s3-object-lambda-9402e400f912
0 Response to "Lambda Function Read Fixed Length Data File to S3"
Post a Comment